Joshua Batty
Evolution of MindBuffer's Performance Apporach 2010-2015
09-08-2016

Overview
The following post outlines the performance iterations undertaken during my research into real-time creation and performance of audiovisual art. Early in my candidature I worked with electronic musician and C++ programmer Mitchell Nordine to create MindBuffer (our performance duo). After writing our first audiovisual track, we were approached and signed to Enig’matik records as a live audiovisual intelligent dance music (IDM) duo. Our aim was to use MindBuffer and Enig’matik records as a platform to produce and perform cutting-edge and tightly synchronised audiovisual musical experiences Each iteration below describes the technological, aesthetic and performance strategies we used for notable national and international MindBuffer performances over the past four years, and concludes with an introduction to the final iteration that was used for my examination performance in December 2014.
Iteration 1 – Brown Alley (Melbourne) 2011
The first MindBuffer show was performed at Brown Alley in Melbourne for the launch of Enig’matik Records, June 24, 2011. A considerable amount of work went into composing music for the hour-long set and programming visuals and a framework that synchronised the music from one laptop with the visuals on a second laptop. Although the performance was not as polished as we would have liked, the initial aesthetic and performance framework created for this performance set the foundation from which the other iterations evolved.

Photograph of MindBuffer’s first gig (Brown Alley, Melbourne, Australia, June 2011)
Performance Strategy
Technically, the performance setup consisted of pre-composed music separated into one of the following four stems: drums, bass, melody and atmosphere. These were exported out of Logic (Apple Computer, California) as either an eight or sixteen-bar phrase. Once all the tracks were exported, the stems were imported into Ableton Live and arranged to create appropriate mixes. In order to synchronise the musical elements with the visuals, I created a Max4Live device to analyse the volume data in Ableton and send it over a network using OSC. The custom Max4Live device was then inserted onto the drums, bass, melody and atmosphere tracks.
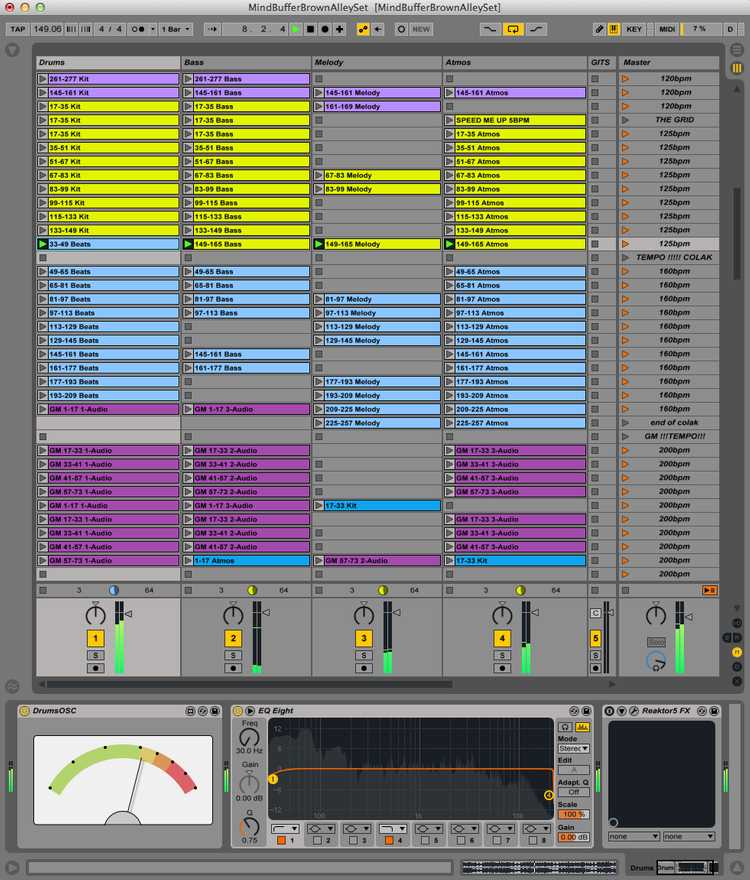
MindBuffer Ableton set showing each track divided into Drums, Bass, Melody and Atmosphere stems with a Max4Live device on each track on the bottom left
The figure below illustrates the framework that was constructed to handle real-time visual sketch triggering and audio synchronisation. At the time, I was unfamiliar with openFrameworks and decided to use Processing to create real-time visual environments that evolved and reacted to auditory data. To maintain visual interest, I programmed seven unique Processing sketches to be triggered as the set evolved. Within each Processing sketch, I identified between four and six visual parameters, such as shape colour, shape speed, shape size etc., to be controlled either by a touch screen interface or by the volume data coming in as OSC from one of the four audio tracks. These parameter assignments were capable of being redefined in real-time during a performance using a custom interface I created for the JazzMutant Lemur touch screen controller.
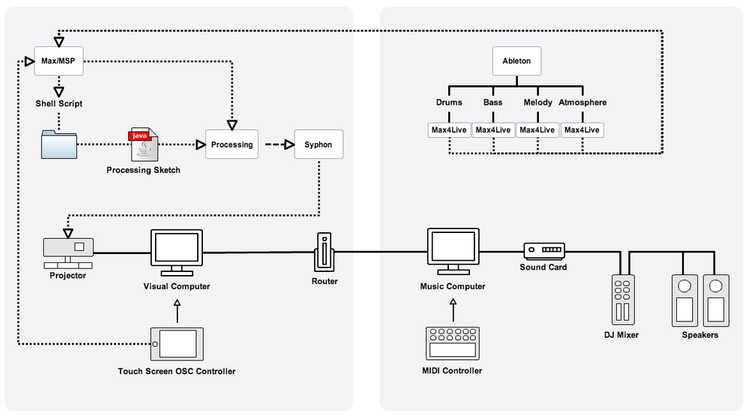
Initial performance framework for synchronising audio and visuals between two laptops
After playing one sketch, to load the next, I triggered the name on the touch screen to send OSC data to a Max/MSP patch. The Max patch identified the incoming message which was then sent into a message box containing a shell script to find and load the corresponding processing sketch. I then manually compiled the code onstage and instructed Syphon to switch its visual output to the new sketch.
What Worked
The technique of using Max4Live to send independent volume data for the drums, bass, melody and atmosphere enabled flexible synchronisation of audiovisual relationships. During the performance I was able to reassign specific auditory control to a variety of visual parameters in real-time from my controller. This enabled me to emphasise musical phrases and transitions by assigning visual aesthetics to specific instrumentation as the composition evolved.
What Didn’t Work
Although the Max4Live synchronisation technique generated interesting visual results, the lack of preparation and rehearsal time before this performance meant there was a great deal of trial and error when assigning a musical element to an appropriate visual aesthetic.
The Jazz Mutant Lemur touch screen interface programmed for this performance did not meet my expectations as a performance interface. In order to manipulate a visual parameter I needed to focus on positioning my finger on the correct slider. This diverted my attention from the media I was controlling. The inability to engage simultaneously with the performance interface and the visual media led me to conclude that non-tactile performance interfaces do not facilitate intuitive control of visual media in a performance setting. As a result, I decided that a MIDI controller interface featuring physical knobs and sliders would alleviate this limitation for future performances.
Compiling code live onstage did not help the fluidity of the performance. Furthermore, the framework’s reliance on a multitude of different software environments not only led to potential confusion but also increased the risk of technical failure. If one part of the signal chain crashed, the whole framework could fail to work correctly, requiring a quick restart at best, or at worst, cease to perform for the remainder of the set. The technological risk associated with such a hacked bleeding edge framework highlighted the need for a unified visual performance environment.
Iteration 2 – Eclipse Festival (Cairns) 2012
MindBuffer was invited to perform at the weeklong total solar eclipse festival held outside of Cairns, Australia, 10–16th November 2012. We were booked to play a one-hour live audiovisual set and to open for Richard Devine, one of my most significant creative influences in the field of IDM. I spent three months redesigning the framework used in the earlier performance, aiming not only to overcome the limitations of the previous iteration but to expand the range of visual aesthetics capable of being assigned to audio synchronisation.

Mindbuffer set at Eclipse Festival (Cairns, Australia, November 2012)
Performance Strategy
I wanted to alleviate the previous iteration’s dependence on multiple pieces of software needed to handle loading, manipulating and displaying visual imagery throughout the set. To achieve this I created a unified framework using openFrameworks. The design of the framework was heavily inspired by my experience with a popular VJ’ing application called VDMX. In VDMX, the user is able to assign and play back visual content on two independent channels that can then be mixed or blended together to create visual collages, or to assist with transitions between visual media. I adopted this design concept and programmed a collection of different blend modes inspired by those found in Photoshop. This enabled me to blend video files that contained interesting visual textures, such as complex fractal patterns, into the visual audio reactive synthesisers I had programmed for the set.
In addition to creating a unified environment, my goal was to maximise the potential for visual complexity whilst still achieving the highest possible frame rate. To achieve this, I programmed the audio reactive visual synthesisers and effects using a low-level programming language that ran on the GPU as shaders. Implementing shaders to handle the real-time visual synthesis generation and visual post-processing effects enabled a higher-quality and better-performing visual output than the previous iteration. This process also facilitated my creation of a complex visual signal processing effects chain that enabled further deconstruction of the image. Visual effects were controlled independently using my controller or synchronised by routing one of the four incoming audio tracks.
Finally, for this performance, I exchanged the touch screen controller for a physical MIDI controller. This was done in recognition of the need for a tactile performance interface that became evident during reflection on the previous iteration. Using Max/MSP, I programmed a variety of states that enabled changing the colour of specific pads on the controller in order to obtain visual feedback regarding the current visual synthesiser and audiovisual assignments. The figure below shows the complex interconnectedness between various functions which enabled this visual feedback to occur. Although my aim was to eradicate the reliance on secondary software in order to reduce the complexity of the performance framework, I did not at this point possess the required C++ knowledge to implement this specific functionality.
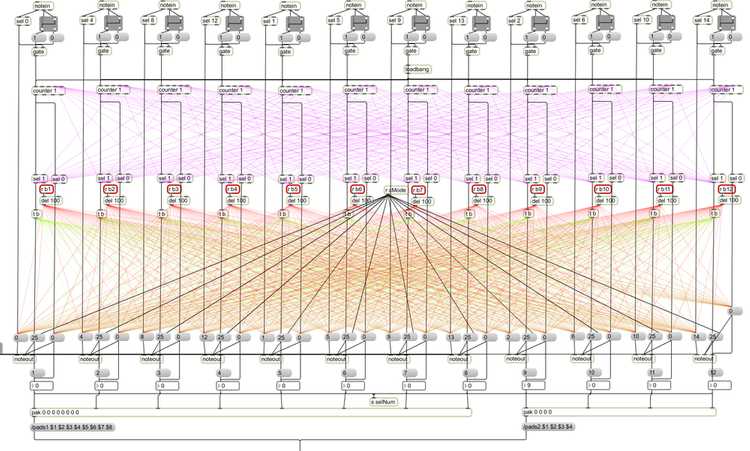
Custom Max/MSP patch that enabled coloured visual feedback on the midi controller.
What Worked
I found the tactile feedback of the MIDI controller offered a greater level of expressiveness and playability with the visual media than the touch screen controller. This tactility was developed from my experience as a trumpet and piano player, and also from the ability to engage with visual media while manipulating the physical interface. The visual feedback I programmed into the pads on the controller enabled me to quickly see the current audiovisual assignments. Consequently, I was able to perform with the audiovisual assignments in a more expressive manner.
A more responsive and convincing synchronisation of audio and visuals was achieved through the process of eliminating multiple software dependency by creating a unified environment in openFrameworks. The integration of implementing visual synths and effects as shaders that ran on the GPU not only resulted in a huge performance boost, but increased visual detail and expanded the audio synchronisation possibilities to include visual post-processing effects.
What Didn't Work
During the performance I found myself wanting an even greater level of sensitivity with the controller. I could only perform audiovisual re-assignments at the end of musical phrases which usually meant every 8 or 32 bars of music. Although I could perform manipulations over various visual aesthetics using the physical sliders, the linear manipulations offered by the sliders did not allow me to synchronise and engage with the highly rhythmic parts of our music. For this to occur in a future iteration, I needed to rhythmically perform with the music by making better use of the middle 16 pads.
Finally, I was not satisfied with the range of visual material available throughout the one-hour performance. It took too long to program the new framework from scratch and the visual complexity of the shader synths was limited as a result of my basic understanding of the OpenGL Shading Language (GLSL). For this performance I created eight visual synths to trigger as the set evolved. This equated roughly to one visual synth per one and a half musical compositions. Although I was able to reassign audiovisual relationships during pivotal moments in a composition, there were instances when the composition dramatically changed its direction and intent, specifically at breakdowns and drops. As a result, I was unable to match the same emotional and aesthetic range visually within each composition.
Iteration 3 – Burning Man (Nevada) 2013
MindBuffer was invited to perform three live audiovisual sets at the annual Burning Man festival held in Black Rock, Nevada on 26th August – 2nd September. The festival is one of the most prestigious art and electronic music festivals in the world and we were very pleased to be booked to play there for our first-ever international gig.
Each performance invitation came from a unique sound camp located within the festival. As a result, our audiovisual set had to be flexible enough to adapt easily to the varying stage setups that each camp had at their disposal. Furthermore, the Burning Man site is held on a very inhospitable geographic location. The environment is made up of fine corrosive alkaline dust particles that tend to clog delicate electronic performance instruments. After hearing stories about the corrosive dust wrecking the technical gear of past performers, we needed to ensure that we protected our equipment from sudden dust storms during a performance. This was achieved by using painters’ tape on the laptop speakers and any unused ports, and by covering our gear in bubble wrap, as shown below.
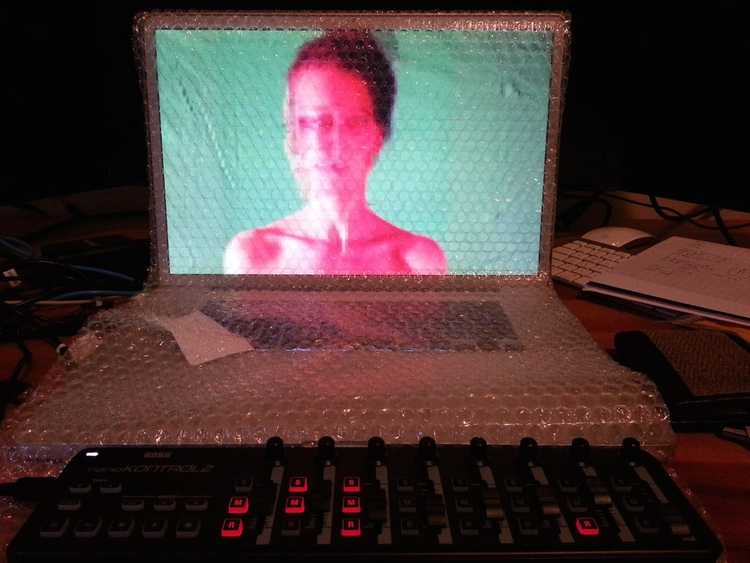
Burning Man Laptop Protection
Performance Strategy
We were booked to perform one-and-a-half-hour sets for each of the three events at Burning Man – thirty minutes longer than any of our previous sets. Up until then, I had only used a collection of visual shader synths for the performances because I did not feel the visual granular synthesis technique was stable enough in a live performance setting. However I managed to swap content in and out of the visual granular synthesis engine and, due to the extra 30 minutes of content needed to fill the set, I decided to trail a combination of both visual shader synths and visual granular synthesis for these performances.
In order to tighten the synchronisation between the music and visuals, I programmed another Max4Live device that sent a pulse over OSC at the beginning of each musical phrase. During the past two iterations, I could only receive information about the drums, bass, melody and atmosphere’s current volume. Expanding the assignable data to include information about the beginning of musical phrases allowed the visual aesthetics to react not only to a stream of volume data but to macro compositional information.
The framework was further developed to allow saving audiovisual assignments as presets to be recalled and triggered during a performance. When switching from one visual synth to another, appropriate audiovisual assignments for a previous scene would not work aesthetically with the new scene. To address this I triggered a new visual synth at pivotal moments in the set, such as the beginning of a new track. The contrast from one scene to another helped to reinforce the new direction of the music. Utilising presets helped to maximise this effect by automatically switching the audiovisual assignments to the most appropriate relationships for the newly triggered visual synth.
What Worked
Aesthetically, several of the refinements produced noticeable improvements over previous iterations. The ability to instantly trigger predefined audiovisual assignment presets facilitated powerful high- level interactions during the performances. Additionally, utilising the musical phrase data provided an ability to achieve dramatic synchronised changes to the visual aesthetic. In doing so, the visuals evolved from merely reacting to the instrument’s volume data (as is the case with popular media player visualisers) to achieving a more convincing perceivable relationship with the musical composition itself. The juxtaposition of visual granular synthesis alongside the visual shader synths enabled a wider visual aesthetic and proved to be a useful performance tool for exaggerating sudden musical changes at pivotal moments during the set.
What Didn't Work
The harsh natural environment, along with the different technical setups each stage provided, meant our performances at Burning Man were very challenging. The first stage setup featured multiple non-rectangular small projection surfaces. Because I became aware of this only a few hours before the show, I had to re-program the framework to enable multiple visual outputs for the show later that night.
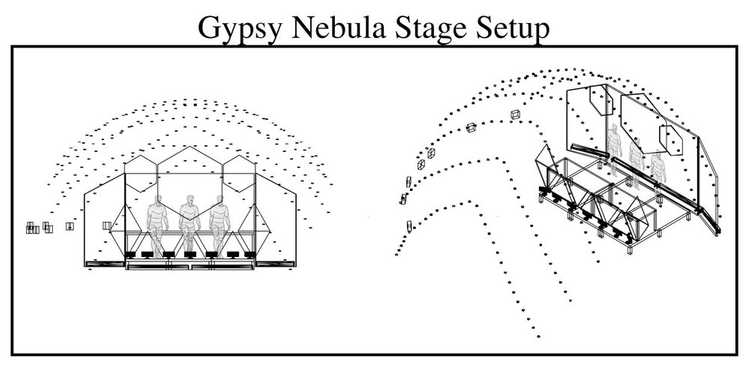
Gypsy Nebula stage plan displaying the three non-rectangular projection surfaces, dotted lines represent stage enclosure
In contrast, the stage for our second performance (seen below) featured an enormous 70 m wide by 30 m high concave projection arena. Unfortunately, the HDMI input for the projections could only be reached at the front of house while the audio input was on top of the projection wall. This meant my colleague and I were separated during the performance by a distance of roughly 70m. As a result, not only were we unable to communicate during the performance, but more significantly, the OSC messages we relied on for audiovisual synchronisation could not be sent over an ethernet connection. Although this was not ideal, we created an ad-hoc network connection that was capable of sending 90% of the OSC data wirelessly from his laptop to mine, enabling a convincing synchronisation to occur.

MindBuffer Burning Man set 2, photo taken from my performance perspective, (30th August, Nevada, 2013)

Seventy metre wide stage during the MindBuffer set at Burning Man (30th August, Nevada, 2013)
Iteration 4 – UFO Club (Sydney) 2014
We were invited back by the UFO Club to perform our live audiovisual set in Sydney in January 2014. The performance was our second night in a row opening for the London musician Vaetxh on his East Coast tour. The promoters told us that they were going to construct three large projection surfaces, engulfing the performers and audience in a “cave of screens”. As a result, I decided to use this performance as an opportunity to debut not only the triple-screen capabilities of my research project instrument Kortex but to debut my new powerful mini-ITX desktop computer.
Performance Strategy
Up until this iteration, I had been developing Kortex as a software environment separate to the one I had been developing for the live MindBuffer performances. Although the two shared similarities, such as their visual post-processing effects, the live MindBuffer software was responsible for creating audio reactive visual shader synths, while Kortex’s sole purpose was the creation of AVGS. The previous iteration proved that visual granular synthesis and visual shader synths could work harmoniously together. Consequently, I upgraded Kortex’s functionality by merging in the previous iteration’s visual shader synth framework.
Several new technological and aesthetic features became possible as a result of merging the visual shader synths into Kortex. Kortex was already capable of rendering to three unique visual outputs. This meant I was able to now render the visual synths in either monophonic mode (one synth stretched over three screens) or in polyphonic mode (three unique synths per screen). At the same time, the huge performance advantage my modern desktop computer had over my 2011 MacBook Pro laptop allowed me to upgrade the resolution from a single 512×512 render canvas to three 1024×1024 render canvasses.
For this iteration, I reprogrammed all of the pre-set triggering and visual feedback for the MIDI controller to reach my goal of creating a unified environment. Consequently I was able to remove the dependency on Max/MSP and simplify the process of sending and receiving controller data with Kortex. As a result, I developed a feature called PadModes to expand the functionality of the middle bank of pads on the controller. PadModes (see Figure below) was developed to address my desire to rhythmically interact with the music and visuals during a performance. In doing so, I was able to rectify the performance flaw that became evident after reflecting on the performance of Iteration 2.
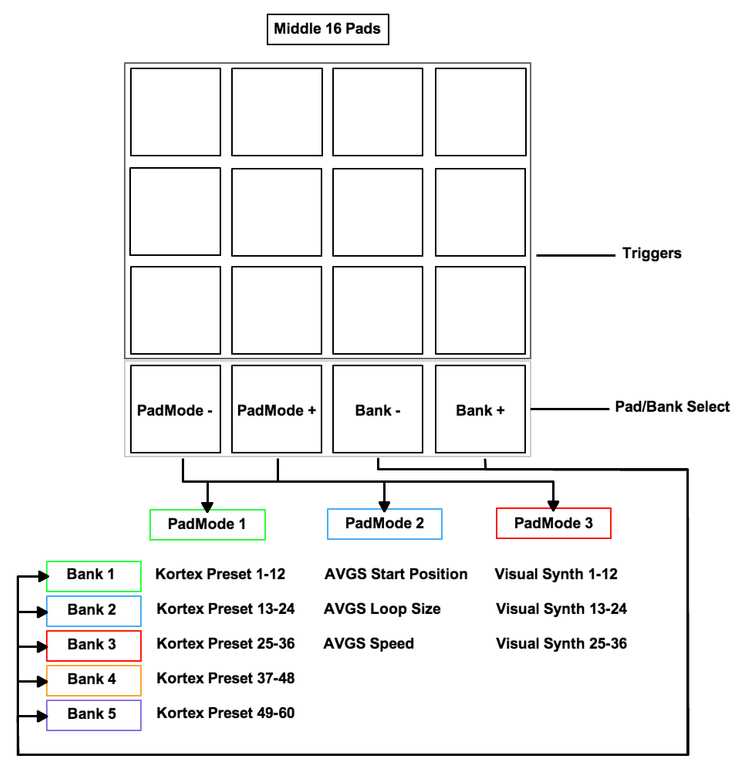
PadMode MIDI controller mappings to enable rhythmic triggering functionality
What Worked
The opportunity to output audio reactive visuals over multiple screens, along with doubling the visual resolution, contributed towards the audience experiencing a high degree of sensory immersion. Throughout the set, I switched between monovisual and polyvisual output rendering modes. For example, at times I had three unique visual shader synths reacting to the music during a high-energy musical phrase. When I knew a breakdown was approaching at the end of the musical phrase, I assigned the phrase OSC trigger to instantly switch the rendering mode to immerse the audience within a single widescreen visual shader synth. The contrast in visual perception matched the contrast in musical direction, further reinforcing the perceived integration between the music and visuals.
From a performance standpoint, my familiarity with the controller mappings, the musical set and the inclusion of PadMode functionality enabled me to interact with Kortex just as any musician interacts with their instrument. I was able to approach manipulating the visuals in much the same way a drummer improvises rhythmically in a musical performance. At certain times during the performance I was able to switch between creating different visual polyrhythms in relation to the rhythmical activity of the composition. For example, when the music contained fast rhythmical phrases I was able to trigger visual elements using a half-time feel, and then resynchronise with the original tempo during the last bar of the phrase. This approach felt very natural to me as a musician even though the media I was improvising with was visual. The rhythmical interplay between the musical and visual media seemed to enhance and reinforce the stylistic and emotional intent of the compositions.
What Didn't Work
Despite the many positive audiovisual synchronisation enhancements that occurred during the four iterations, I was still not completely convinced the visuals were a true representation of the musical compositions. Even though the volume data from the four music stems and the phrase data were producing pleasing results, I was not satisfied knowing that an even larger amount of micro and macro musical events were occurring in the track and could be used for visual synchronisation. For example, a wide range of rhythmical visual aesthetics is not possible using only the summed volume of the entire drum track. Far more interesting results could emerge by sending unique volume data for the kick drum, snare drum and hi-hats individually. In doing so, the visual aesthetics could be more intricately connected and reinforce the audience’s perception of the audiovisual relationships.
Finally, for this performance I was unable to manually select the polyvisual output to contain a combination of both visual granular synthesis and visual shader synths simultaneously. I needed to address this in order to heighten the technique’s ability to induce a feeling of sensory immersion for the final iteration.
Introduction to the Final Iteration – Examination (Melbourne) 2014
My examination performance held in Melbourne during December 2014 was the final iteration to take place within the time frame of my candidature. The final technological design and compositional practice iteration evolved from a four-year cyclical process of action and reflection regarding the real-time performance and creation of audiovisual art. The performance strategy outlined below addresses the required enhancements that became evident during reflection on the previous iterations. Furthermore, it describes the final performance framework developed to achieve the goals and aims of my research.
Performance Strategy
The musical compositions for the previous four iterations were first composed in Logic and Ableton Live and then arranged in Ableton to achieve smooth transitions from one song to the next during a performance. This approach guaranteed the ideal compositional arrangement of our music and ensured a steady momentum during the one-hour performances. However, two undesirable factors were inherent within this approach. Firstly, the personal satisfaction gained from performing the set decayed exponentially with each performance; this was especially so during our three sets at Burning Man within the space of four days. Secondly, the approach used in the previous iterations restricted the range of musical information that could be analysed by Max4Live and used for visual synchronisation; the micro and macro compositional structure, and each instrumental voice’s digital signal processing data, were unable to synchronise with the visual imagery. To alleviate the repetition of replaying the same set, and to facilitate complete integration of sound and image at the micro and macro compositional level, I needed to implement a dramatic shift in approach.
This was achieved through using a custom generative musical composition environment created by Nordine (2014) in C++ using openFrameworks. Named Jennifer Max, it was affectionately referred to simply as Jen. Jen can be used to create an infinite range of musical compositions based on high-level user directives. The user specifies musical parameters such as intricacy, complexity, time signature and tempo that are then used to generate a unique musical composition. As everything is being synthesised and generated in real-time, there is no need to prepare stems or .wav files, eradicating any of the previous iteration’s reliance on external commercial software packages. Most importantly, to enable audiovisual synchronisation, Jen sends the entire hierarchy of track information ranging from bar subdivisions to overall song position as well as the volume, pitch and position information for each musical voice via OSC.
In order to synchronise Kortex with Jen, I developed a separate openFrameworks add-on called JenOSC. In short, JenOSC is a modular patching environment for creating relationships between incoming music data from Jen and specific visual aesthetics in Kortex. Combinations of user defined audiovisual relationships are then stored into a bank of presets that can be recalled during a performance. The central philosophy of this approach is that every single musical event on both the micro and macro scale has a direct potential influence over a visual aesthetic. Consequently this approach redefines my performance role from the position of a single instrumentalist to a higher (macro) level, similar to that of an orchestral conductor. More specifically, my performance role is to create the ideal conditions throughout the performance for audiovisual synchresis to occur.
The above approach will be used for the first time to synchronise AVGS with musical events. Although previous iterations partially implemented visual granular synthesis, this iteration will debut the accompanying audio of the AVGS technique developed for my research. In doing so, the AVGS synchronised with Jen will take on the foreground performance role, similar to that of the soloist in a band. Synchronising the AVGS technique with meaningful musical events provides the necessary context that had been missing up until this iteration. Without musical context, the audiovisual aesthetics slide in and out of timeless states and, although interesting results emerge which would suffice for an interactive installation, alone it is not enough to hold an audience’s attention for the duration of a one-hour performance. Clearly this is a result of the specific context in which AVGS is applied. In a sit-down performance the performer is required to hold the audience’s attention much longer than if AVGS was used for an installation where the audience can decide how long they want to engage with the content.
The novelty of experiencing AVGS in the context of musical events will decay in the audience unless contrasting aesthetics are provided. To overcome this, AVGS will have time to feature in parallel with the visual shader synths and by utilising the triple projection surfaces. Interesting visual aesthetics will emerge as a result of the complex interplay between simultaneous visualisation of the two techniques. For example, both AVGS and the visual shader synths will have periods of mutual visibility and periods of exclusive visibility over the range of the three projection surfaces. In this way, through creatively assigning spatial combinations of monovisual and polyvisual imagery, the audience will be able to engage more broadly throughout the duration of the performance and experience a greater degree of sensory immersion.
As a result of the generative framework outlined above, this performance will be a unique unrepeatable experience much in the same way a jazz ensemble never replicates a performance. The framework facilitates the conditions for spontaneous musical and visual aesthetics to emerge from the software that will then influence new ideas in myself as the performer. This setup creates a tri-directional improvisatory feedback loop between the computer, myself and the audience. Most significantly, the framework developed for the final iteration enables the creation and performance of audiovisual art in real-time.
Final performance for PhD examination (December 2014)
Summary
Above I have discussed my action and reflection performance cycle through highlighting four national and international performances that took place during my candidature. For each performance iteration, I described the performance strategy I employed to evolve the Kortex framework and provide a critical self-reflection of the performance outcomes. Some of the most important highlights that emerged were:
• The tactile nature of MIDI controllers facilitate more intuitive control as a performance interface than touch screen interfaces
• Integrating audio and visual functionality within a single performance framework reduces technological risk and complexity
• Both micro and macro musical data are required to produce a convincing synchronous visual representation of a musical composition
• Synchronising AVGS with musical events frames the technique and provides necessary context
• Utilising contrasting audiovisual aesthetics helps to maintain the audience’s interest throughout a performance.